
Git은 어떤 원리로 동작하는가?
Git의 원리를 알기 위해 .git의 내부를 살펴보자.
git init 명령어를 사용하면 .git 디렉토리가 생성된다.
gistory라는 프로그램을 이용하면 .git 디렉토리의 내용을 리스트로 보여준다.
gistory 설치
python을 설치한다.
sudo pip3 install gistory.git디렉토리로 이동gistory를 입력
브라우저에서
http://0.0.0.0:8805/에 접속
git add
파일을 추가한 뒤 gistory 화면을 리로드해도 아무런 변화가 없다.
하지만 git add 명령어로 추가한 파일을 전달하면 다음과 같이 2개의 항목이 추가가된 것을 확인할 수 있다.
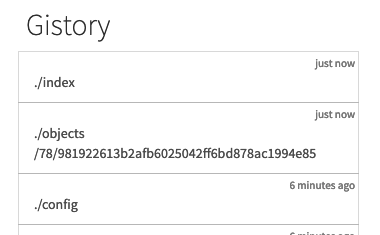
추가된 ./objects/.... 디렉토리를 클릭하면 우측에 추가한 파일인 t1.txt의 내용이 담겨져있음을 알 수 있다.

파일의 이름은 gistory가 편의상 보여준 것이고 ./objects 디렉토리 안에 적혀있지는 않다. 이름은 그 위에 있는 ./index에 적혀있다.
 즉 파일의 이름은
즉 파일의 이름은 ./index에, 파일의 내용은 ./objects에 담겨있다. 그 디렉토리 안에 담겨있는 파일들을 객체, Object라고 한다.
파일을 하나 더 추가해본다. 오브젝트가 하나 더 추가가되고, ./index에도 해당 파일에 대한 정보가 추가된다.


기존의 파일을 복사해본다.
$ cp t1.txt t3.txt


./index를 확인해보면 t1.txt와 t3.txt가 같은 object를 가리키고 있음을 알 수 있다. git은 파일을 저장할 때 파일의 이름이 달라도 파일의 내용이 같다면 같은 object를 가리킨다.
object의 파일명의 원리
git은 우리가 작업하는 파일의 내용을 SHA1이라는 해시 알고리즘을 통과시켜서 만든 해시값에서 앞 2글자만 떼서 object 디렉토리 안에 디렉토리를 만든다. 그리고 2글자 이후 값을 이름으로 파일을 만들어 내용을 저장한다.
그래서 어떤 파일에 대해 git add를 이용하면, git은 파일의 내용을 압축하고 SHA1이라는 방법으로 해시값을 만들고 그 값에 해당되는 정보를 ./objects 디렉토리 안에 만들고, 내용을 저장하는 것이다.
commit의 원리
git add 후, git commit을 하면, 다음과 같이 많은 파일이 생성되었음을 확인할 수 있다.

./objects 디렉토리 내부의 파일 중 하나에 commit에 대한 정보가 담겨져있다.

commit 또한 .git 디렉토리 안에 저장된다. 즉 commit도 Object이다. tree에는 Object 정보가 담겨있다. 해당 버전에 해당되는 파일의 이름과 내용이 연결되어있다.

파일을 새로 수정하고, 다시 commit을 하고 그 commit object를 살펴보면 이전에 없었던 parent가 추가된 것을 확인할 수 있다. parent에는 이전 commit이 연결되어 있다.


commit에는 이전 commit이 어떤 것인지 확인하는 parent와 그 commit이 일어난 시점의 파일 이름과 내용 사이의 정보가 tree에 담겨있다.
각각의 버전은 서로 다른 tree가 담겨 있고, tree에는 파일 내용과 파일 이름이 담겨 있어 버전의 tree를 이용해 버전이 만들어진 시점의 상태를 얻어낼 수 있는 것이다. 각각의 버전이 만들어진 스냅샷을 tree라는 구조에 담는 것이다.
디렉토리를 추가해 동일한 파일을 copy하면 내용이 같기 때문에, ./index에서 같은 Object를 가리키고 있다.
$ cp t1.txt d1/t1.txt
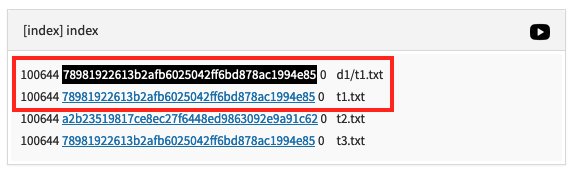
./objects 디렉토리 안의 Object 파일들은 크게 3가지 중 하나다. 하나는 파일의 내용을 담은 blob, 디렉토리의 파일의 이름과 내용(blob)을 담은 tree, 그리고 commit
status의 원리
현재 가장 최신 commit과 ./index를 비교하면 commit할 것이 있는지 없는지 확인할 수 있다.
./index에 있는 값과 현재 파일의 내용이 만들어내는 값이 다르다면, 해당 파일이 수정되었다는 것을 알 수 있다. 변경된 파일을 git add로 commit 대상에 포함시키면, git은 ./index의 내용과 commit 대상에 포함시킨 파일이 같으니, commit 대기 상태임을 알 수 있다.
그리고 git은 ./index의 내용과 가장 최신 commit의 tree가 가리키는 내용이 다른 것을 확인해 commit 대기 상태인 것을 알 수 있다.
branch
소프트웨어 개발 프로젝트를 진행하면 개발자들이 동일한 소스코드를 작업을 하는데, 각각 작업을 하다보면 서로 다른 버전의 코드가 만들어진다. 이럴때 동시에 작업을 진행할 수 있게 해주는 기능이 브랜치(Branch)이다. 분리된 작업 영역에서 작업을 하고 나중에 원래의 버전과 비교해 하나의 버전을 만들 수도 있다. 각각의 브랜치는 다른 브랜치의 영향을 받지 않아 여러 작업을 동시에 할 수 있다. 또 병합(Merge)해서 하나의 브랜치로 합칠 수도 있다.
Head
git init 후 ./HEAD라는 파일을 살펴보면 다음과 같다. refs/heads/master라는 파일을 가리키는데 아직 그 파일은 없다.

파일을 하나 commit 하고 나면 ref/heads/master라는 파일이 생성되어 있다. commit한 내용이 담겨져있다.

한번 더 수정 후 commit하면 refs/heads/master에 방금 commit한 내용이 담겨져있다. 가장 최신 commit이 들어가는 것을 확인할 수 있다.

git log를 입력하면 HEAD 파일을 통해 가장 최신 commit을 알게되고 그 commit 의 parent를 통해 이전 commit을 탐색할 수 있는 것이다.

branch를 하나 추가해보고 gistory를 확인해보면 refs/heads/exp가 생성되고 이 파일은 master 브랜치처럼 최신 commit을 가지고 있다.
$ git branch exp

git에서 branch라는 것은 .git 내부의 파일인 것이다.
다음과 같이 branch 이동하면 ./HEAD 파일이 refs/heads/exp를 가리키게 된다.
$ git checkout exp
 결국 Head라는 것은 현재 checkout한 최신 commit을 가리키는 것이다.
결국 Head라는 것은 현재 checkout한 최신 commit을 가리키는 것이다.
reset:refs/heads/브랜치명파일의 commit id를 변경한다.
Tag
Tag는 Branch와 비슷한듯 다르다. Release 라는 것은 사용자에게 제공되는 의미있는 버전을 말한다. 해당 버전이 어떤 commit인지 확인할 필요가 있다. 그때 사용하는 것이 Tag이다.
$ git tag 1.0.0 master$ git tag
 Tag의 종류는 2가지 이다. 이름만 붙이는 일반 태그(Lightweight tag)와 주석 태그(Annotated tag)이다.
Tag의 종류는 2가지 이다. 이름만 붙이는 일반 태그(Lightweight tag)와 주석 태그(Annotated tag)이다.
Tag 명령어
태그 목록 보기
git tag
태그 생성 (light weight tag)
git tag "태그 이름" [태그가 가르킬 버전의 커밋 아이디]
태그 생성 (annotated tag)
git tag -a "태그 이름" -m "태그에 대한 설명" [태그가 가르킬 버전의 커밋 아이디]
태그 삭제
git tag -d "삭제할 태그명"
태그 원격 저장소로 업로드
git push --tags