
이모지의 이모저모
웹에 접속하는 매일, 이모지(Emoji)를 보지 않는 날이 없다. 그만큼 이모지는 생활에 깊숙이 들어왔다.
이모지는 다른 문자와 뭐가 다른 걸까? 어떻게 표시되는 걸까? 이모지에 대해 생긴 궁금증을 해결해 보고자 한다.
이모지

이모지는 감정, 기호 또는 사물을 나타내는 데 사용되는 그림 문자다. 원래는 일본 휴대폰에서 사용했지만 지금은 전 세계적으로 사용된다. "이모지"란 이름은 일본어 絵文字(emoji)에서 왔다. 絵(에)는 그림을, 文字(모지)는 문자를 의미한다.
이모티콘 ?
예전부터 감정을 나타내는 문자를 "이모티콘"이라 불렀는데, 스마트폰을 사용했을 때쯤 "이모지"란 단어가 불쑥 나타났다. 2가지가 무슨 차이가 있는지 궁금했다.
이모티콘은 "emotion" + "icon"으로 이메일과 문자 메시지에서 감정을 전달하기 위해 사용했다. 예를 들면 :-), :-(와 같은 것들이다. 이모지는 이름에서 알 수 있듯이 감정뿐 아니라 다른 기호나 사물들을 표현하는 "그림 문자"인 것이다. 근데 보통 이 말도 쓰고 저 말도 쓰는 것 같아 보인다.
유니코드와 UTF
컴퓨터에서 데이터는 0과 1로 표현된다. 문자를 0과 1로 저장하는 것을 "문자 인코딩" 이라 한다. 그럼 어떤 데이터는 왜 일반 문자로 표시되고 이모지는 그림이 나타나는 걸까? 우선 컴퓨터에서 문자를 표현하기 위해 어떤 방법을 사용하는지 알아보자!

1960년대에 "Teleprinter"라는 기기가 있었다고 한다. 어린 시절에 타자기를 본 적이 있었는데 그와 비슷하게 생겼다.
Teleprinter는 전보를 부치기 위해 글을 입력해서 그걸 전기 신호로 바꾼 뒤, 받는 쪽에서 출력하는 기계다.
문자가 전기 신호로 변환되기 위해 숫자로 변환이 될 텐데 이 숫자를 보내는 방법에 표준이 필요해서 미국에서 ASCII라는 표준을 만들었다. 표준이 필요한 이유는 어떤 숫자를 보내면 받는 쪽에선 이게 어떤 문자를 의미하는지 판단하는 기준이 되기 때문이다.
ASCII는 7개의 bit를 사용한다. 키보드로 치는 각 글자가 7bit 이진수로 변경돼서 전선을 타고 상대방에게 전송된다. 7bit이기 때문에 사용할 수 있는 숫자는 0에서 127이다.
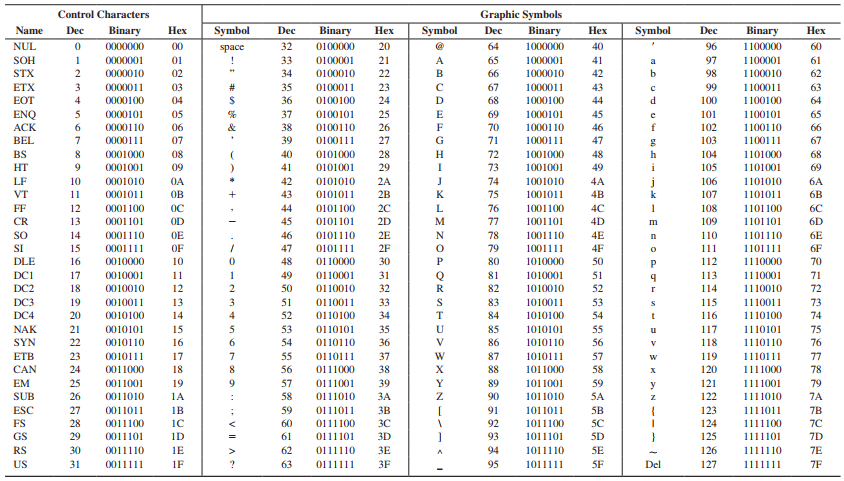
위 ASCII 코드표를 확인하면 알 수 있듯이 처음 32개 숫자는 줄바꿈 문자, 백스페이스 등을 배당하고 그 뒤로 특수 문자들과 숫자를, 65부터 알파벳이 들어간다.
여기서 하나의 특징은 A는 65라는 숫자에 배당했기 때문에 이진수를 봤을 때 마지막 숫자 2개만 확인해서 몇 번째 알파벳인지 확인할 수 있었다는 점이다.
1000001 // A1000010 // B1000011 // C1100001 // a1100010 // b1100011 // c
영어권 국가에서는 알파벳을 사용하기 때문에 표준으로 정착되었지만 알파벳을 사용하지 않는 언어들을 만나 문제가 생겨났다. 그래서 해당 언어들은 각자의 인코딩 방식을 사용했다. 예를 들어 한글은 EUC-KR 인코딩 방식을 사용했다.
그리고 시간은 흘러 World Wide Web이 등장했고, 다양한 문자가 포함된 문서들이 전 세계 곳곳에서 전송되기 시작했다! 진정한 표준이 필요한 시기가 찾아온 것이다.
이때 유니코드라는 것이 나왔다. 유니코드는 유니코드 컨소시엄이라는 비영리 단체에서 관리하는데 전 세계 모든 문자를 표현하기 위해서 각 문자에 고유한 코드 포인트(숫자)를 할당한다.
예를 들어
- 한글
ㄱ은U+1100에 할당되어 있고 - 이모지
🐶는U+1F415에 할당되어 있다.


접두사 U+는 유니코드를 의미하고 1F415는 16진수로 된 코드 포인트다.
문자를 0과 1로 저장하는 것을 "문자 인코딩"이라고 했다. UTF는 유니코드를 인코딩하는 방식이다. 즉, 코드 포인트를 컴퓨터 메모리에 저장하는 방식이다.
UTF 인코딩의 동작은 이 영상에서 자세히 확인할 수 있다.
UTF 인코딩도 여러 가지 방식으로 나뉘는데, UTF-8도 있고 UTF-16, UTF-32 등이 있다.
UTF-32를 예로 들면, 이름에서 알 수 있듯이 코드 포인트를 32bit로 저장하는 것이다. 따라서 U+1F415는 00 01 F4 15가 되고 메모리에서 4byte를 차지한다.
그래서 이모지는 왜 그림으로 표현되는 거지?
이모지와 기타 다른 문자들은 유니코드의 각 코드 포인트에 할당되어 있기 때문에 별 차이는 없어 보인다. 그래서 내가 '이모지는 그림인데!'라고 외쳐봤자 이모지도 각각이 하나의 문자인 것이다. 그렇지만 마음이 답답하다. 이모지는... 이미지이기 때문이다. 색상이 있고 화려하다. 검은색으로만 된 문자란 다르다는 사실이 내 마음을 더 답답하게 만들었다. 하지만 다음과 같은 사실을 알게 되었다.
이모지는 글꼴이다.
0과 1로 저장된 데이터를 사람이 읽을 수 있도록 문자 체계로 변환해 화면에 표시해 주는 것을 우리는 글꼴(폰트)라 부른다.
글꼴 파일에서 문자 하나하나를 "글리프"라 하는데, 각 글리프에 이미지를 넣을 수 있다.
mac에서 서체 관리자 앱을 열어보면 "Apple Color Emoji"라는 글꼴과 함께 3605개 글리프를 가지고 있다는 설명도 볼 수 있다.


Variation Selector
어떤 이모지들은 이미 예전부터 유니코드에 존재했었다. 예를 들어, ❤는 코드 포인트가 U+2764로 1993년부터 존재했다. 이모지에도 ❤️가 있다. 이모지를 위한 글꼴 말고도 다른 글꼴에도 해당 코드 포인트가 존재한다는 것이다. 그럼 운영체제는 둘 중 어떤 글꼴을 렌더링 해야 하는지 결정하는 것일까?
여기서 Variation Selector(U+FE0F)가 필요하다. ❤️도 코드 포인트가 U+2764지만 문자 뒤에 U+FE0F가 있다. 그래서 다르게 렌더링 된다.
Zero Width Joiner
이모지에 대해 알아보면서 ZWJ(Zero Width Joiner)라는 것을 알게 되었다. 가장 신기했던 부분이다.
여기 북극곰 이모지가 있다.
const polarBear = '🐻❄️'
이 polarBear 변수에 spread 문법을 사용해 보자.
;[...polarBear] // ['🐻', '', '❄', '️']
4개의 배열로 나눠지면서 첫 번째로 🐻, 두 번째로 빈 문자열, 세 번째는 ❄ , 네 번째로 빈 문자열이 나온다. 🐻❄️ 는 두 가지 이모지를 조합해서 만들어지는 것 같아 보인다!
그렇다면 빈 문자열은 무엇일까? 정말 빈 문자열인지 확인해 보자.
JavaScript에서 charCodeAt을 사용하면 주어진 index에 해당하는 유니코드 값을 얻을 수 있다.
const [bear, one, snow, two] = [...polarBear]one.charCodeAt(0) // 8205two.charCodeAt(0) // 65039
유니코드 8205는 ZWJ(zero with joiner)이고 65039는 앞에서 살펴봤던 variation selector다. ❄ 문자는 이미 존재하는 문자이기에 ❄️ 이모지로 표현하려면 이게 필요했던 것이다.
그럼 🐻 이모지와 ❄️ 이모지를 합치기 위해서는 ZWJ를 사용했다는 사실을 알 수 있다.
이걸 따로 변수에 담아서 테스트해 보자.
const [bear, ZWJ, snow, VARIATION_SELECTOR] = [...polarBear]const woman = '👩'const rice = '🌾'[(woman, ZWJ, rice)].join('') // 👩🌾
이처럼 이모지는 하나로 결합을 할 수 있다! 이모지 조합을 'Emoji ZWJ Sequence'라 한다. 모든 이모지가 조합이 가능한 것은 아니지만 다양한 조합이 가능하다.
어쨌거나 문자열 배열로 만들 수 있기 때문에 배열 메서드를 사용해 다음 동작도 가능하다.
'👨👩👦'.replace('👦', '👧') // 👨👩👧
이모지 알쓸신잡
이모지에 대해 알아보면서 개발할 때 알아두면 쓸 데 없긴 하지만 그래도 알게 된 것들이 몇 가지 있다.
Database
첫 번째는 내가 실제로 겪었던 문제인데 MySQL에서 텍스트 데이터에 이모지를 저장하고 싶었는데 에러가 발생하는 문제가 있었다.
이건 MySQL이 UTF-8을 구현했을 때 3 byte 문자만 저장할 수 있어서 생긴 문제였다. 그래서 DBMS의 인코딩을 utf8mb4로 변경해야 했다. (참고)
이모지의 길이
이모지 뿐만 아니라 유니코드에서 여러 코드 포인트로 조합된 문자를 제대로 다루지 않으면 다음과 같은 버그가 발생할 수도 있다:

codepen의 에디터인데 이모지 하나(🐻❄️)를 지우는데 4번의 키 스트로크가 필요했다. 지우고 나니 "🐻"가 나오는 걸 보니 앞에서 spread 문법으로 나눠지는 각 요소가 하나의 문자로 간주되지 않는 듯 보인다.
길이를 구할 때도 문제가 있다. JavaScript에서 문자열의 길이를 구할 때 length 메서드를 사용한다. 다음 코드를 살펴보자.
const a = 'a'const b = '가'const c = '🚀'a.length // 1b.length // 1c.length // 2
c 변수에 할당한 이모지는 하나임에도 불구하고 예상과 다르게 길이가 2가 나온다. 이게 무슨 일일까?
JavaScript는 문자열을 UTF-16으로 다루기 때문이다. 🚀의 유니코드는 U+1F680고 UTF-32로 인코딩하면 0001F680, UTF-16로 인코딩하면 0xD83D와 0xDE80이라고 한다. 그래서 길이가 2가 되는 것이다.
Lodash는 toArray로 이 문제를 해결했다고 한다.
import _ from 'lodash'_.toArray('🐻❄️북극곰').length // 4
DeppL 번역앱의 확장 프로그램도,

맞춤법 검사기도 깨져서 나온다.

그리고 Terminal에서도 이와 비슷한 문제가 있다고 한다.
검색창 자동완성
구글 검색창에 이모지를 입력해도 자동완성이 된다.

쿠팡은 🐻❄️를 검색했는데 🐻가 자동완성된다.

하지만 🐻만 입력하면 자동완성이 되지 않는다.

bing은 🐻❄️ 만 자동완성된다.

🐻를 검색하면 다른 곰들도 나온다.

자동완성 기능을 구현할 때 문자열을 처리하는 방식에 따라 다양하게 동작하나 보다. 왜 그런지는 좀 더 탐구해야겠지만 이유가 있지 않을까?
글을 마치며
이모지와 인코딩을 아주 얕게 공부했다. 더 깊이 공부해야 할 필요성을 느낀다. 그러고 나면 마지막에 서비스마다 자동완성이 다르게 나오는 이유에 대해서도 알 수 있을 것이다!
reference
- Unicode와 UTF-8 간단히 이해하기
- https://gist.github.com/mandel59/d05522cdb42a652bf423
- Zero Width Joiner
- The Absolute Minimum Every Software Developer Must Know About Unicode in 2023
- What is the unicode variation selector